

全站爬虫有时候做起来其实比较容易,因为规则相对容易建立起来,只需要做好反爬就可以了,今天咱们爬取知乎。继续使用scrapy当然对于这个小需求来说,使用scrapy确实用了牛刀,不过毕竟这个系列到这个阶段需要不断使用scrapy进行过度,so,我写了一会就写完了。
你第一步找一个爬取种子,算作爬虫入口
https://www.zhihu.com/people/zhang-jia-wei/following
我们需要的信息如下,所有的框图都是我们需要的信息。
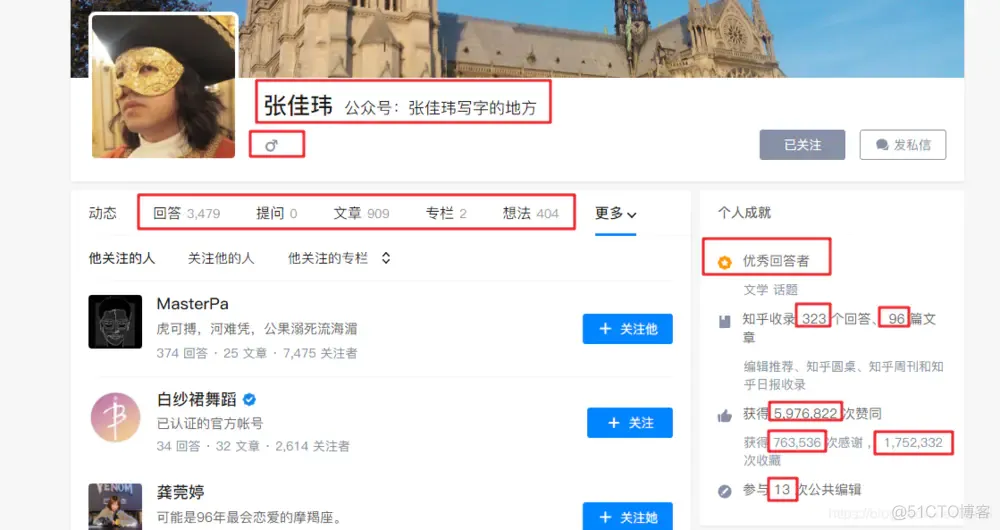
获取用户关注名单
通过如下代码获取网页返回数据,会发现数据是由HTML+JSON拼接而成,增加了很多解析成本
class ZhihuSpider(scrapy.Spider): name = ‘Zhihu’ allowed_domains = [‘www.zhihu.com’] start_urls = [‘https://www.zhihu.com/people/zhang-jia-wei/following’]
def parse(self, response): all_data = response.body_as_unicode() print(all_data)
首先配置一下基本的环境,比如间隔秒数,爬取的UA,是否存储cookies,启用随机UA的中间件DOWNLOADER_MIDDLEWARES
middlewares.py 文件
from zhihu.settings import USER_AGENT_LIST # 导入中间件 import random
class RandomUserAgentMiddleware(object): def process_request(self, request, spider): rand_use = random.choice(USER_AGENT_LIST) if rand_use: request.headers.setdefault(‘User-Agent’, rand_use) Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
setting.py 文件
BOT_NAME = ‘zhihu’
SPIDER_MODULES = [‘zhihu.spiders’] NEWSPIDER_MODULE = ‘zhihu.spiders’ USER_AGENT_LIST=[ # 可以写多个,测试用,写了一个 "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36" ] # Obey robots.txt rules ROBOTSTXT_OBEY = False # See also autothrottle settings and docs DOWNLOAD_DELAY = 2 # Disable cookies (enabled by default) COOKIES_ENABLED = False # Override the default request headers: DEFAULT_REQUEST_HEADERS = { ‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’, ‘Accept-Language’: ‘en’, } # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { ‘zhihu.middlewares.RandomUserAgentMiddleware’: 400, } # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { ‘zhihu.pipelines.ZhihuPipeline’: 300, }
主要爬取函数,内容说明
# 起始位置 def start_requests(self): for url in self.start_urls: yield scrapy.Request(url.format("zhang-jia-wei"), callback=self.parse)
def parse(self, response):
print("正在获取 {} 信息".format(response.url)) all_data = response.body_as_unicode()
select = Selector(response)
# 所有知乎用户都具备的信息 username = select.xpath("//span[@class=’ProfileHeader-name’]/text()").extract_first() # 获取用户昵称 sex = select.xpath("//div[@class=’ProfileHeader-iconWrapper’]/svg/@class").extract() if len(sex) > 0: sex = 1 if str(sex[0]).find("male") else 0 else: sex = -1 answers = select.xpath("//li[@aria-controls=’Profile-answers’]/a/span/text()").extract_first() asks = select.xpath("//li[@aria-controls=’Profile-asks’]/a/span/text()").extract_first() posts = select.xpath("//li[@aria-controls=’Profile-posts’]/a/span/text()").extract_first() columns = select.xpath("//li[@aria-controls=’Profile-columns’]/a/span/text()").extract_first() pins = select.xpath("//li[@aria-controls=’Profile-pins’]/a/span/text()").extract_first() # 用户有可能设置了隐私,必须登录之后看到,或者记录cookie! follwers = select.xpath("//strong[@class=’NumberBoard-itemValue’]/@title").extract()
item = ZhihuItem() item["username"] = username item["sex"] = sex item["answers"] = answers item["asks"] = asks item["posts"] = posts item["columns"] = columns item["pins"] = pins item["follwering"] = follwers[0] if len(follwers) > 0 else 0 item["follwers"] = follwers[1] if len(follwers) > 0 else 0
yield item
# 获取第一页关注者列表 pattern = re.compile(‘<script id=\"js-initialData\" type=\"text/json\">(.*?)<\/script>’) json_data = pattern.search(all_data).group(1) if json_data: users = json.loads(json_data)["initialState"]["entities"]["users"] for user in users: yield scrapy.Request(self.start_urls[0].format(user),callback=self.parse, dont_filter=False) Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
在获取数据的时候,我绕开了一部分数据,这部分数据可以通过正则表达式去匹配。
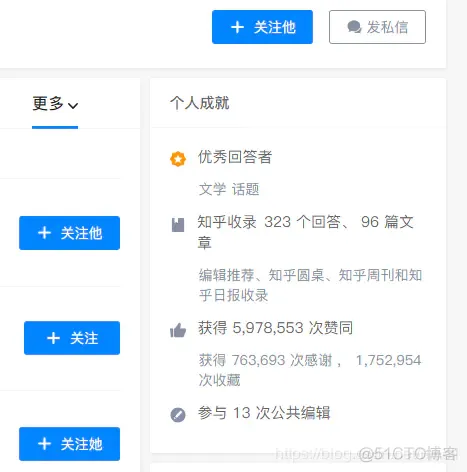
数据存储,采用的依旧是mongodb
神龙|纯净稳定代理IP免费测试>>>>>>>>天启|企业级代理IP免费测试>>>>>>>>IPIPGO|全球住宅代理IP免费测试



